


Lexical density measures word frequency within text.
That sentence had a lexical density of 100%, but it's a little hard to understand. Let's unpack it.
Lexical density, in the context of text analysis, is a metric that quantifies the proportion of significant or content-bearing words, such as nouns, verbs, adjectives, and adverbs, compared to the total number of words in a piece of text.
Ok, that's a lot easier to understand, but the lexical density here is now only ~56%.
Lexical Density is just one metric linguists use to analyze text. There are tons of other interesting ways to analyze writing. This post will provide an introduction to some of these metrics, and how to calculate them in JavaScript.
Intro
Hey there, I'm Joseph, a senior developer advocate at Appsmith, and I must warn you, I am NOT a linguist! No, I'm just a JavaScript developer who happened to build an app for a university study a few years ago, went down the rabbit hole, and learned some basics about text analysis along the way. So if you see any missing or inaccurate information in this post, please feel free to drop a comment below. This is mostly uncharted territory for me, but I'm diving in, and loving the combination of programming and written language.
NOTE: Appsmith recently added support for ESM Libraries, which is what inspired me to dive back into this subject when I found a few new libraries to use in Appsmith.
Calculating Lexical Density
In it's most basic form, this is just a ratio of unique words / total words. Just split the text by spaces,
function calculateLexicalDensity(text='testing, testing, one, two, three') {
const words = text.split(/\s+/);
const uniqueWords = new Set(words); // Use a Set to store unique words
const lexicalDensity = (uniqueWords.size / words.length) * 100;
return lexicalDensity;
}
// returns 80In this example we have 5 word, but one repeats. So 4/5 = 80% Lexical Density. However, this simple function would return 100% if the first 'Testing' were capitalized because Set() is case sensitive. It also doesn't filter out those non-important words like, in, of, and, the, etc. Let's fix that!
function calculateLexicalDensity(text, skipWords = ["a","an","the","in","on","at","of","for"]) {
const words = text.split(/\s+/);
const uniqueWords = new Set();
words.forEach(word => {
const lowerCaseWord = word.toLowerCase();
if (!skipWords.includes(lowerCaseWord)) {
uniqueWords.add(lowerCaseWord);
}
});
const lexicalDensity = (uniqueWords.size / words.length) * 100;
return lexicalDensity;
}
// Example usage:
const inputText = "This is a super basic example of lexical density calculation. This is a test.";
const skipWords = ["is", "a", "this", "of"];
const density = calculateLexicalDensity(inputText, skipWords);
console.log(`Lexical Density: ${density.toFixed(2)}%`);Flesch-Kincaid Readability Score
Next up, we'll look at the Flesch-Kincaid Readability Score, which uses a similar ratio calculation, but this time we'll also need the number of syllables. This is just a simple function call with the syllable.js library.
countSyllables(string='testing, one, two three') {
//https://cdn.jsdelivr.net/npm/syllable@5.0.1/+esm
return syllable.syllable(string);
}
// returns 5The Flesh-Kincaid formula compares the number of syllables to the number of words:

And in JavaScript:
// Function to calculate the Flesch-Kincaid readability score
calculateFleschKincaid(text) {
const doc = compromise(text);
const words = doc.terms().out('array');
const numWords = words.length;
const numSentences = doc.sentences().length;
const totalSyllables = words.reduce((total, word) => total + this.countSyllables(word), 0);
const avgSyllablesPerWord = totalSyllables / numWords;
const fleschKincaid = 0.39 * (numWords / numSentences) + 11.8 * avgSyllablesPerWord - 15.59;
return fleschKincaid.toFixed(2); // Round to two decimal places
}I took the copy from our website and ran it through this function to see where it falls on the readability score. It turns out, you have to be a professional to understand marketing speak about internal tools. I'll have to talk to our marketing team about this.
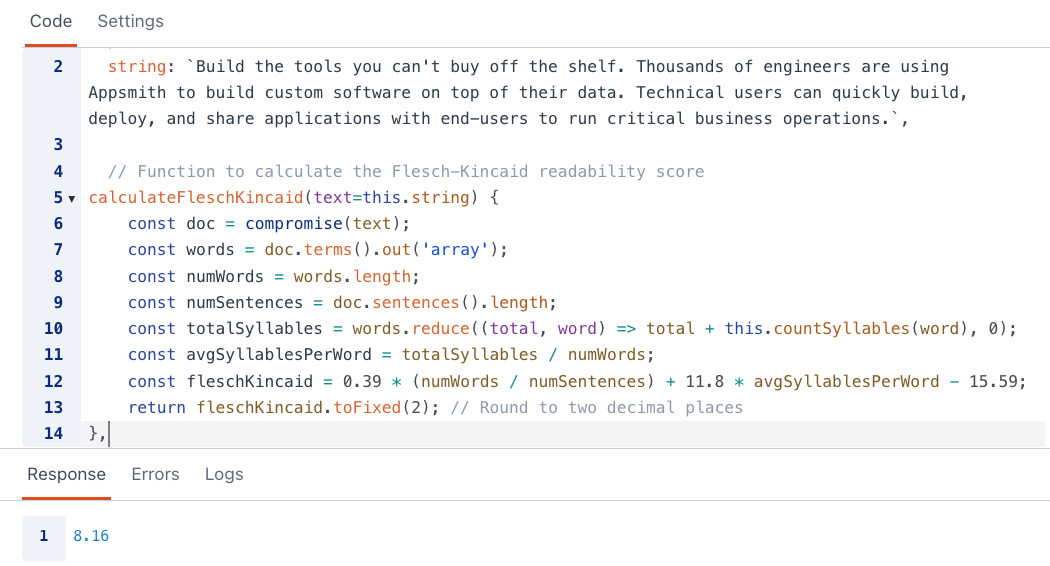
| Score | School level (US) | Notes |
|---|---|---|
| 100.00–90.00 | 5th grade | Very easy to read. Easily understood by an average 11-year-old student. |
| 90.0–80.0 | 6th grade | Easy to read. Conversational English for consumers. |
| 80.0–70.0 | 7th grade | Fairly easy to read. |
| 70.0–60.0 | 8th & 9th grade | Plain English. Easily understood by 13- to 15-year-old students. |
| 60.0–50.0 | 10th to 12th grade | Fairly difficult to read. |
| 50.0–30.0 | College | Difficult to read. |
| 30.0–10.0 | College graduate | Very difficult to read. Best understood by university graduates. |
| 10.0–0.0 | Professional | Extremely difficult to read. Best understood by university graduates. |
String Similarity
How about comparing two strings? This can be useful for catching misspellings, grading, or even building a text based game. So how do you compare two strings in JavaScript? Like most things in programming, there are lots of ways. But more importantly, there are a bunch of different methodologies for comparison, separate from the programming approach. As such, this section would be massive if I tried to make it comprehensive. Instead, here's a high level summary of the possible methods, and a few examples.
| Method | Description | Difficulty in JS | Related JS Libraries |
|---|---|---|---|
| Levenshtein Distance | Measures edit operations to transform one string into another. | Moderate | fast-levenshtein, natural |
| Jaccard Similarity | Calculates set similarity by comparing elements' intersections. | Easy | None |
| Cosine Similarity | Computes similarity between vector representations of strings. | Moderate | math.js, ml-cosine |
| Hamming Distance | Counts differing characters in equal-length strings. | Easy | None |
| Dice Coefficient | Measures similarity using character bigrams. | Easy | None |
| Jaro-Winkler Distance | Designed for comparing human names, considering transpositions. | Moderate | string-similarity |
| Soundex and Metaphone | Phonetically encodes words to compare pronunciation. | Easy | soundex, double-metaphone |
| N-grams and Q-grams | Divides strings into character sequences for comparison. | Easy | None |
| Damerau-Levenshtein Distance | Extends Levenshtein with transposition consideration. | Moderate | None |
| Longest Common Subsequence (LCS) | Measures the length of the longest shared subsequence. | Moderate | None |
| Smith-Waterman Algorithm | Used for local sequence alignment in biological and text data. | Difficult | needleman-wunsch |
| Fuzzy Matching Algorithms | Utilizes approximate string matching techniques. | Moderate | fuzzywuzzy, similarity |
| Jaro Distance | Similar to Jaro-Winkler but without the prefix scaling factor. | Easy | jaro-winkler |
| Q-grams with Jaccard Similarity | Applies Jaccard similarity to Q-grams for string comparison. | Easy | None |
Jaccard Similarity
This one is easy in JavaScript, no libraries needed. Just find the intersections of the arrays created by splitting the strings into word arrays.
jaccardSimilarity(str1='I build apps', str2='apps that fill gaps') {
const set1 = new Set(str1.split(' '));
const set2 = new Set(str2.split(' '));
const intersection = new Set([...set1].filter(x => set2.has(x)));
const union = new Set([...set1, ...set2]);
const similarity = intersection.size / union.size;
return similarity;
}Levenshtein Distance
This one is easy to understand, but the JS is a bit advanced. Conceptually, the Levenshtein Distance is just the number of single character edits needed to change from one string to the other. The distance between Cat and Bat is 1, and API and IPA is 2.
The code, however, is some matrix wizardry that I have yet to fully understand. I did get the code working though. Thanks ChatGPT. 🤝🤖
levenshteinDistance(str1='Cat', str2='Bat') {
const len1 = str1.length;
const len2 = str2.length;
const matrix = [];
for (let i = 0; i <= len1; i++) {
matrix[i] = [i];
}
for (let j = 0; j <= len2; j++) {
matrix[0][j] = j;
}
for (let i = 1; i <= len1; i++) {
for (let j = 1; j <= len2; j++) {
const cost = str1[i - 1] !== str2[j - 1] ? 1 : 0;
matrix[i][j] = Math.min(
matrix[i - 1][j] + 1, // Deletion
matrix[i][j - 1] + 1, // Insertion
matrix[i - 1][j - 1] + cost // Substitution or no change
);
}
}
return matrix[len1][len2];
}Sentiment Analysis
Sentiment analysis, also known as opinion mining, is a natural language processing (NLP) technique used to determine the sentiment or emotional tone expressed in a piece of text, whether it's positive, negative, or neutral. It's widely employed in various applications such as social media monitoring, customer feedback analysis, and content recommendation.
Sentiment analysis can be classified into three main categories:
- Positive Sentiment: Indicates a positive emotional tone or favorable opinion.
- Negative Sentiment: Indicates a negative emotional tone or unfavorable opinion.
- Neutral Sentiment: Represents a lack of strong emotional tone, typically neither positive nor negative.
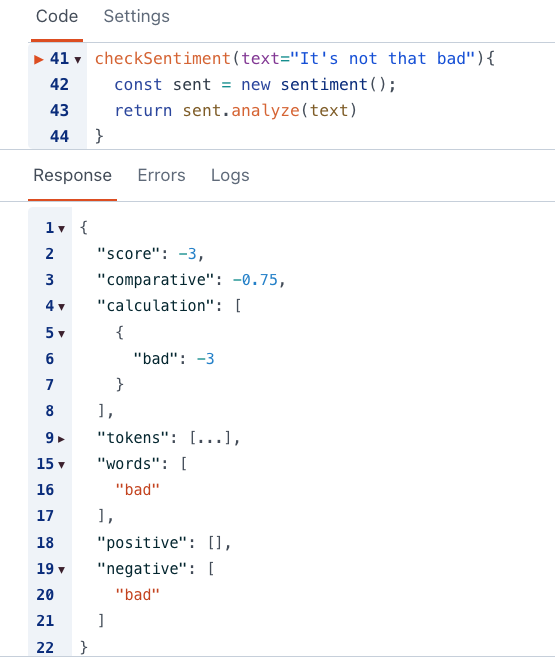
checkSentiment(text="It's not that bad"){
//https://cdn.jsdelivr.net/npm/sentiment@5.0.2/+esm
const sent = new sentiment();
return sent.analyze(text)
}Basic sentiment analysis works by looking for key words, and assuming they are being used in a certain context. But in this example, not that bad is a positive expression. Yet the sentiment.js library still flags it as negative.
In cases like this, a better approach would be to use OpenAI's API for text analysis.
Text Cohesion
Text cohesion refers to how different parts of a text are interconnected and logically structured to ensure clarity and coherence. Cohesive texts use techniques such as transitional words, pronouns, repetition, and logical organization to guide readers through the content smoothly, making it easier to understand.
Here's a simple JavaScript example that calculates a basic measure of text cohesion by counting the number of transitional words (e.g., "however," "therefore") used in a text:
function calculateTextCohesion(text) {
// List of common transitional words
const transitionalWords = ["however", "therefore", "furthermore", "in addition", "consequently", "nevertheless"];
// Tokenize the text into words
const words = text.toLowerCase().split(/\s+/);
// Count the number of transitional words in the text
const transitionalWordCount = words.filter(word => transitionalWords.includes(word)).length;
// Calculate a cohesion score based on the frequency of transitional words
const totalWords = words.length;
const cohesionScore = (transitionalWordCount / totalWords) * 100;
return cohesionScore;
}
// Example usage:
const text = "However, despite the challenges, we persevered. Furthermore, our efforts paid off.";
const cohesionScore = calculateTextCohesion(text);
console.log(`Text Cohesion Score: ${cohesionScore.toFixed(2)}%`);
Conclusion
I hope you've enjoyed this primer on text analysis in JavaScript. In the next post, we'll explore practical applications, and build a custom text analysis app in Appsmith! Thanks for reading and happy app-smithing!



