


Chunking is the process of splitting a larger document into smaller pieces before converting them into vector embeddings for use with large language models. This enables LLMs to process files larger than their context window or token limit, and also improves the accuracy of responses, depending on how the files are split.
In this guide, we'll take an introductory look at chunking documents in JavaScript using LangChain, a JavaScript and Python library for working with LLMs. Chunking documents is just the first step in building a retrieval-augmented generation (RAG) pipeline. This guide will be part of a series on RAG that covers the entire pipeline, with this first post covering some basics on chunking.
This guide will cover:
- Installing LangChain and Compromise in Appsmith
- Uploading Markdown or Text files from the user's device
- Splitting the text into chunks (Character splitting)
- Recursive Text Splitting with LangChain text splitter
- Semantic Splitting with Compromise.js
Let's get chunking!
Check out the template app here.
Installing LangChain in Appsmith
Start out by creating a new Appsmith app, then click the library (cube) icon on the left sidebar. Then click the + to install a new library and use the following CDN link:
https://cdn.jsdelivr.net/npm/@langchain/textsplitters@0.1.0/+esm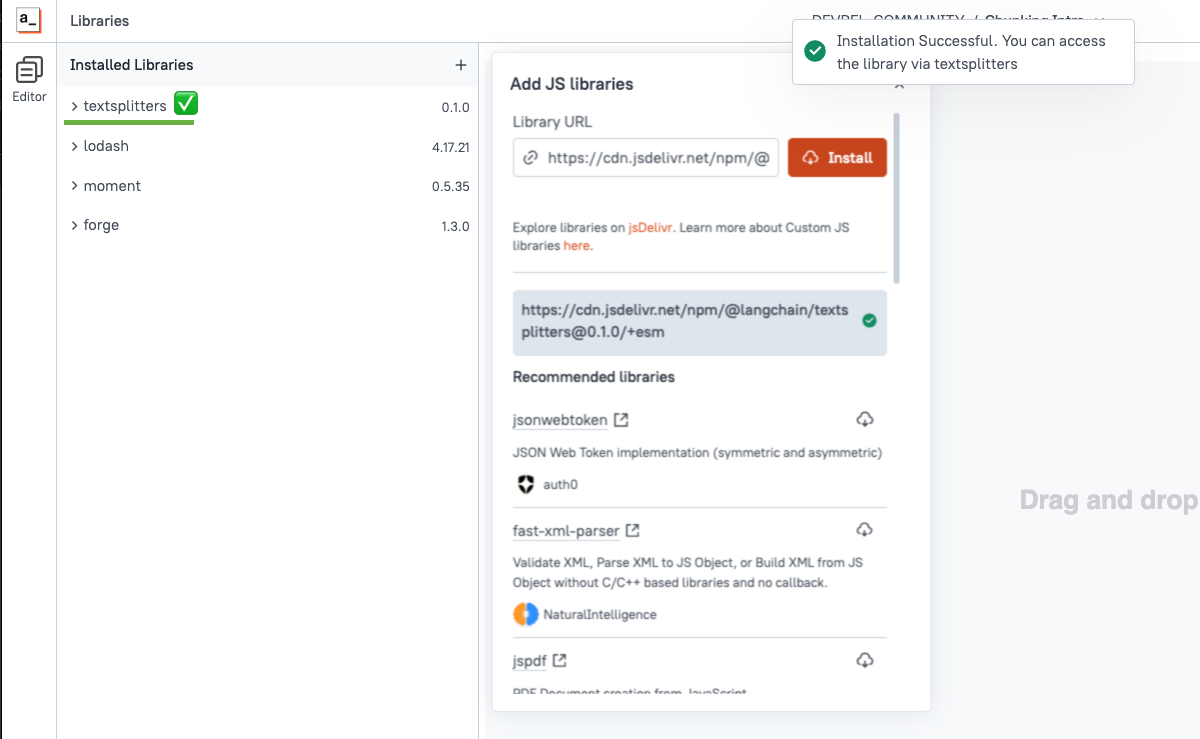
You should see the library added on left. Once installed, the library will be available globally in the app and can be referenced as textsplitters.
Splitting the text into chunks (Character splitting)
Next, go the JS tab in the editor and create a new JSObject. Then paste in the following:
export default {
testString: `# What is Appsmith
Organizations build internal applications such as dashboards, database GUIs, admin panels, approval apps, customer support tools, etc. to help improve their business operations. Appsmith is an open-source developer tool that enables the rapid development of these applications. You can drag and drop pre-built widgets to build UI. Connect securely to your databases & APIs using its datasources. Write business logic to read & write data using queries & JavaScript.
## Why Appsmith[](https://docs.appsmith.com/getting-started/setup/installation-guides/kubernetes/configure-high-availability#why-appsmith "Direct link to Why Appsmith")
Appsmith makes it easy to build a UI that talks to any datasource. You can create anything from simple CRUD apps to complicated multi-step workflows with a few simple steps:
- **Connect Datasource**: Integrate with a database or API. Appsmith supports the most popular databases and REST APIs.
- **Build UI**: Use built-in widgets to build your app layout.
- **Write Logic**: Express your business logic using queries and JavaScript anywhere in the editor.
- **Collaborate, Deploy, Share**: Appsmith supports version control using Git to build apps in collaboration using branches to track and roll back changes. Deploy the app and share it with other users.
## Get started[](https://docs.appsmith.com/getting-started/setup/installation-guides/kubernetes/configure-high-availability#get-started "Direct link to Get started")
1. Create an account on the cloud platform or self-host Appsmith for free.
- [Appsmith Cloud](https://app.appsmith.com/): Sign up for a free account and try Appsmith.
- [Self-Host Appsmith](https://docs.appsmith.com/getting-started/setup): Deploy Appsmith on your local machine or private server.
2. Take the quick tutorial to learn the basics to help you build an app using Appsmith. For more information, see [Build your first app](https://docs.appsmith.com/getting-started/tutorials/start-building).`,
async splitText (text=this.testString) {
const splitter = new textsplitters.CharacterTextSplitter({
chunkSize: 800,
chunkOverlap: 400,
separator: "\n"
})
const chunks = await splitter.splitText(text);
return chunks
}
}This will provide some sample markdown , then create a new splitter using the CharacterTextSplitter method from LangChain. This is the simplest approach, and splits text based on the number of characters without considering document structure or context. To start out with, we're using 800 characters for the chunk size, and 400 for the overlap; the same as the defaults when uploading a file to an OpenAI Assistant.
Note: Using any of the splitter methods in the LangChain textsplitters requires an async function, and awaiting response.
Run the function and you should see an array of 4 chunks returned.

Next, change the chunk size to 8000 and run the function again. This time you'll see the entire text returned in a single chunk. Even though the separator is set to new lines "\n", the text is only split if it exceeds the chunk size.
Uploading Markdown or Text Files from the User's Device
Now head over to the UI tab and drag in a new FilePicker widget. Then set the Data format to Text.
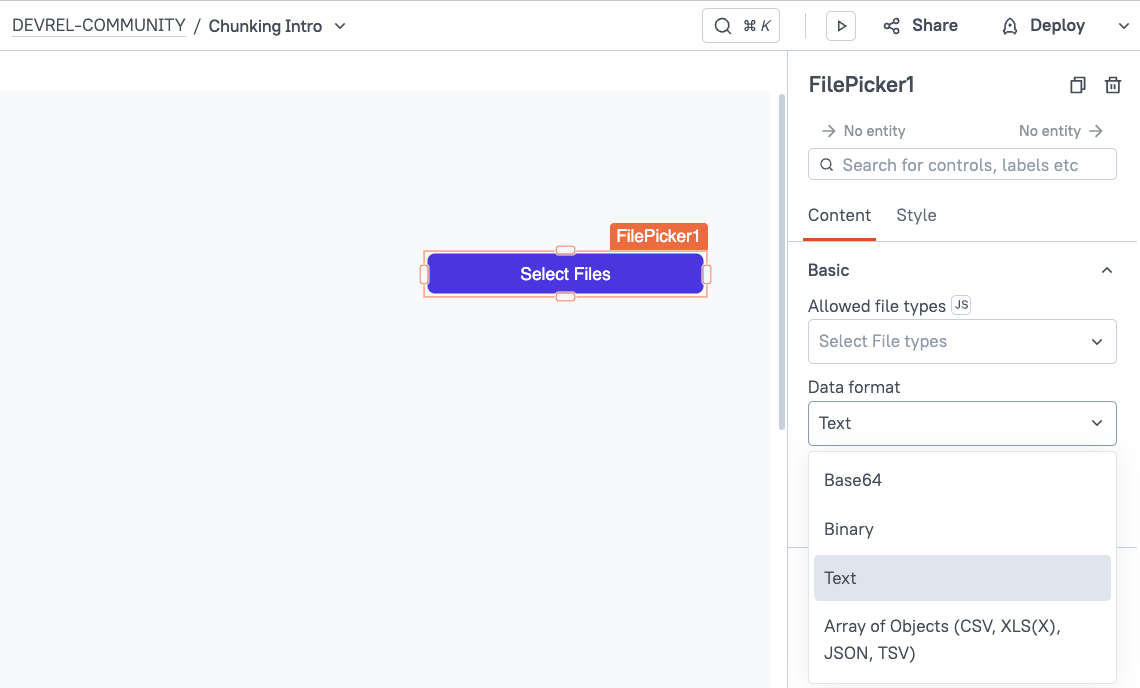
Next, upload a sample markdown or text file from your device. For this guide, I'll be using a markdown file containing the same text as the sample above. You can follow along by saving the same sample text to a new file and saving it as a .md or .txt file.
Now head back to the JS tab and update the splitText function's input to use the FilePicker data for the default value.
text=FilePicker1.files[0].data
Run the function again, and you should get back the same chunks, only coming from the local markdown file this time. You can now delete the sample text, as we'll be working with text from the markdown file for the rest of the guide.
This is the easiest method of splitting text, but it does not produce the best LLM responses because the text is often broken in the middle of a topic, and the context is lost. The other methods all have pros and cons, but plain character splitting really shouldn't ever be used for production.
Recursive Text Splitting
The next method is the RecursiveCharacterTextSplitter. Replace the JSObject with:
export default {
async splitText (text=FilePicker1.files[0].data) {
const splitter = new textsplitters.RecursiveCharacterTextSplitter({
chunkSize: 800,
chunkOverlap: 400,
separators: ["\n\n", "\n", " ", ""]
})
const chunks = await splitter.splitText(text);
return chunks
}
}Note the change in the 3rd parameter (separators), now plural, and an array instead of a single string. This time the text is split by multiple characters, recursively chunking and re-chunking by the next string until the chunk is below the specified chunkSize. A document will first be split by paragraphs (two line returns), and if the chunks are small enough, it will stop there. For chunks still above the chunkSize, it splits again by new lines, spaces, and then characters.
This approach will work on plain text files or markdown, or even text returned from an API or database from an Appsmith query. By splitting recursively, more context is retained with each chunk, and splitting text in the middle of a topic is avoided. However, there are still a few better methods.
Now change the chunkSize to 200 and the chunkOverlap to 100 and rerun the splitText() function. At this level it's easy to see the overlap between the first two chunks.
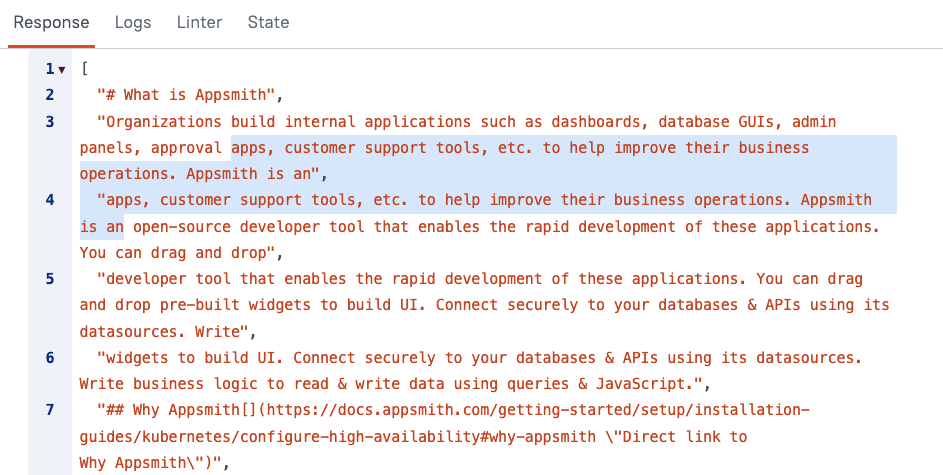
The overlap helps maintain context between chunks and keep the topics connected, but it also increases storage cost, and too much overlap can lead to retrieval noise.
Document Specific Splitting
In this method, the type of document and its structure are considered when choosing where to split text. The easiest example is splitting a markdown file by headers. We can update the separator in the last function with a few new values., specific to our markdown document type.
["\n## ", "\n### ", "\n\n", "\n", " ", ""]Now the text will be split by H2's and H3's first, before splitting by paragraphs, new lines, etc.
Or you could split a CSV into rows using line returns, then split columns by the commas.
async splitCSV(text = FilePicker1.files[0].data) {
// Split text by lines (rows of the CSV)
const rows = text.split("\n");
// Split each row into columns by comma (or other delimiters)
const chunks = rows.map(row => row.split(","));
return chunks; // Returns a 2D array [ [col1, col2, ...], [col1, col2, ...], ... ]
}There are better methods using other libraries to split CSVs, and libraries for reading PDFs and other formats, but for this guide we're only focusing on the markdown example.
Semantic Splitting
This last method involves using an LLM or NPL (natural language processing) to split the text logically based on context. It's best for maintaining context and meaning, but also the most complex, and computationally intensive. We'll stick to a simple example using the Compromise NPL library, and skip the more advanced LLM integration.
First, import the Compromise library from:
https://cdn.jsdelivr.net/npm/compromise@14.14.4/+esmThen add a new function for a semanticSplitter:
async semanticSplitter (text = FilePicker1.files[0].data) {
const doc = compromise(text);
const sentences = doc.sentences().out('array');
// Chunk sentences into larger blocks
const chunkSize = 800;
const chunkOverlap = 400;
let chunks = [];
let currentChunk = [];
for (const sentence of sentences) {
// Add sentences until chunk size exceeds the limit
if (currentChunk.join(" ").length + sentence.length > chunkSize) {
chunks.push(currentChunk.join(" ")); // Save the current chunk
currentChunk = currentChunk.slice(-chunkOverlap / sentence.length); // Keep overlap
}
currentChunk.push(sentence);
}
// Add the last chunk
if (currentChunk.length > 0) {
chunks.push(currentChunk.join(" "));
}
return chunks;
}As you can see, splitting the file into sentences only takes the first few lines of code. The rest of the code builds the individual sentences back up into chunks, as large as possible, without going over the chunkSize. So how is this any better than using a RecursiveTextSplitter and splitting with periods?
The Compromise library (and other NLP libraries) detects patterns in language and splits by actual sentences, avoiding edge cases where a period is used as a decimal, in an ellipsis..., in email addresses, etc. This makes a huge difference in maintaining context!
Conclusion
Chunking is just the first step in building a custom RAG pipeline. Many AI services will handle this for you automatically, but by chunking your own documents, you can have more control and oversight into how your documents are used for retrieval. By understanding the steps and tools involved, you can make adjustments and test the results to optimize your RAG strategy for best results.



